Deploying a Hadoop Cluster




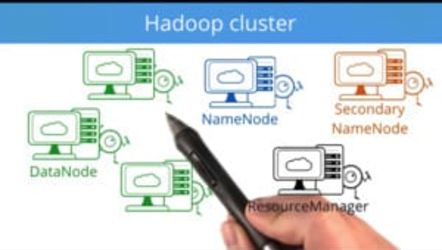
Summary
Learn how to tackle big data problems with your own Hadoop clusters! In this course, you’ll deploy Hadoop clusters in the cloud and use them to gain insights from large datasets.
Expected Learning
Using massive datasets to guide decisions is becoming more and more important for modern businesses. Hadoop and MapReduce are fundamental tools for working with big data. By knowing how to deploy your own Hadoop clusters, you’ll be able to start exploring big data on your own.
Syllabus
Deploying a Hadoop cluster on Amazon EC2
Deploy a small Hadoop cluster on Amazon EC2 instances.
Deploy a Hadoop cluster with Ambari
Use Apache Ambari to automatically deploy a larger, more powerful Hadoop cluster.
On-demand Hadoop clusters
Use Amazon’s ElasticMapReduce to deploy a Hadoop cluster on-demand.
Project: Analyzing a big dataset with Hadoop and MapReduce
Use Hadoop and MapReduce to analyze a 150 GB dataset of Wikipedia page views.
Required Knowledge
This course is intended for students with some experience with Hadoop and MapReduce, Python, and bash commands.
You’ll have to be able to work with HDFS and write MapReduce programs. You can learn about these in our Intro to Hadoop and MapReduce course.
The MapReduce programs in the course are written in Python. It is possible to use Java and other languages, but we suggest using Python, on the level of our Intro to Computer Science course.
You’ll also be using remote cloud machines, so you’ll need to know these bash commands:
- ssh
- scp
- cat
- head/tail
You’ll also need to be able to work in an editor such as vim or nano. You can learn about these in our Linux Command Line Basics course.